Authors: Nagalakshmi & Dr.Mohammed Ali Hussain
ABSTRACT:
In the recent times, managing of Big Data depends on parallel programming representations as well as provision of cloud computing proposal of Big Data services. Big Data is concerned as a promising research area and requirement for Big Data mining is taking place in all of the major domains. To carry out procedure of Big Data mining, containing of competent as well as effectual data access mechanism is extremely important, particularly for users who intend to employ a third party to procedure their data. To get used to huge, active Big Data, researchers prolonged traditional data mining methods in several ways. In our work we recommend a novel approach that differentiates features of Big Data revolution. It put forward significant features of big data and that include: huge with heterogeneous and diverse data sources, large-volume of data represented by varied as well as diverse dimensionalities; Independent data sources by distributed controls
Keywords: Big Data, Heterogeneous, Data mining, Cloud computing, Third party.
- INTRODUCTION:
Because of multiple sources, immense, varied, and active features of application data that are involved in distributed setting, one of most important features of Big Data is to perform computing on data by means of a difficult computing procedure. Utilization of a parallel computing infrastructure, and its equivalent programming language analyze and mine dispersed data are critical goals for dealing with Big Data [1]. Algorithms of data mining typically need to scan all the way through training data for getting of statistics to solve model parameters. For applications that concerns for Big Data and incredible data volumes, it is regularly the situation that data are physically dispersed at various locations, that means users no longer possess storage of their information. Though research efforts confirmed motivating patterns, existing methods can effort in offline fashion and are unable to help to manage Big Data situation in real time. As a result, exceptional data volumes need an effective data analysis as well as prediction proposal to obtain immediate response as well as direct classification for Big Data. In our work we suggest a novel approach that differentiates features of Big Data revolution. To perform the process of Big Data mining, containing of competent as well as effectual data access mechanism is very important, particularly for users who intend to employ a third party to procedure their data. Under such a situation, restrictions of user privacy might include no local data copies, the entire analysis have to be deployed on existing data storage systems devoid of violation of existing privacy settings [2][3]. For most applications of Big Data, privacy concerns mainly spotlight on excluding of third party from accessing original information. General solutions are to depend on a number of privacy-preserving or else encryption methods to defend the data. To get used to immense, energetic Big Data, researchers expanded traditional data mining methods in several ways, including efficiency enhancement of single-source knowledge discovery techniques, scheming of data mining method from a multisource viewpoint in addition to studying of dynamic data mining techniques as well as examination of stream data. The most important motivation for discovering knowledge from immense data is getting better of the effectiveness of single-source mining methods.
- METHODOLOGY:
By techniques of Big Data, we provide most applicable and most precise social sensing response for recognizing our society at real time. Big Data mining recommends chances to move off from conventional relational databases to depend on less structured information. For exploring of Big Data, we have to analyze various challenges at data, model, as well as system levels. For supporting of Big Data mining, extreme computing platforms are necessary, which enforce organized designs to set free complete power of Big Data. Big Data comes from self-governing sources with tricky and developing relationships, varied sources of data. For managing of big data regarding database system, necessary key is to expand to remarkably huge volume of data and suggest treatments for quality featured by our approach. In our work we suggest a novel approach that differentiates features of Big Data revolution. Our method suggests important features of big data and that include: huge with heterogeneous and diverse data sources, large-volume of data represented by varied as well as diverse dimensionalities; Independent data sources by distributed controls; and tricky and developing relationships in data [4]. Being self-governing, each of data source produces and gather information devoid of involving any centralized control. The autonomous sources and variety of data collection setting, often effect in data with complex circumstances. In other circumstances, privacy concerns as well as errors are introduced into data, to make altered data copies. At model level, important challenge is generation of global models by means of combination of locally discovered patterns to structure a unifying view. This necessitates designed algorithms for analyzing of model correlations among distributed sites to gain a finest model out of Big Data [5]. Algorithms of data mining typically need to scan all the way through training data for getting of statistics to solve model parameters. At system level, necessary challenge is that a Big Data mining structure needs to believe complex associations among samples, models, as well as data sources, all along with their developing changes by time as well as other factors.
- ANOVERVIEW OF PROPOSED SYSTEM:
Big Data comes from outsized volume, independent sources with complicated and developing relationships, and various sources of data. In several situations, knowledge extraction process must be tremendously competent as storing the entire observed statistics is almost infeasible. A system has to be carefully considered with the intention that unstructured data is linked all the way through their complex associations to form useful patterns, and expansion of data volumes have to help to structure genuine patterns to expect trend as well as future. An approach was considered that includes demand driven combination of information sources, consideration of privacy and security, mining and analysis. In structure of big data processing that consists of data accessing and computing functions as group-I, data privacy as well as domain knowledge acts as group-II and algorithms of Big Data mining acts as group-III. While big data are stored at a variety of locations and data volumes might constantly grow, useful computing platform should consider dispersed important data storage into concern for computing. The challenges of data mining focus on algorithm designs for managing difficulties that are raised by big data volumes as well as active data features. In data mining systems, mining events require computational intensive units for data comparisons. The challenges at accessing and computing functions spotlight on data accessing as well as arithmetic computing procedures. The challenges at data privacy as well as domain knowledge focus on semantics as well as domain knowledge for various applications of Big Data and this data offers added benefits to mining procedure, in addition to adding of technical barriers towards Big Data access as well as mining algorithms. The challenges ocnconcerning data mining centre of attention on algorithm designs for managing difficulties that are raised by Big Data volumes as well as dynamic data features. Sharing of data privacy Information is a vital goal for the entire systems involving several parties. Information sharing is not an assurance of soft development of every stage, but moreover a function of Big Data processing. Depending on a variety of domain applications, data privacy as well as information sharing methods among data producers as well as consumers can be significantly diverse [6]. For supervision of big data regarding database system necessary key is to expand to remarkably huge volume of data.
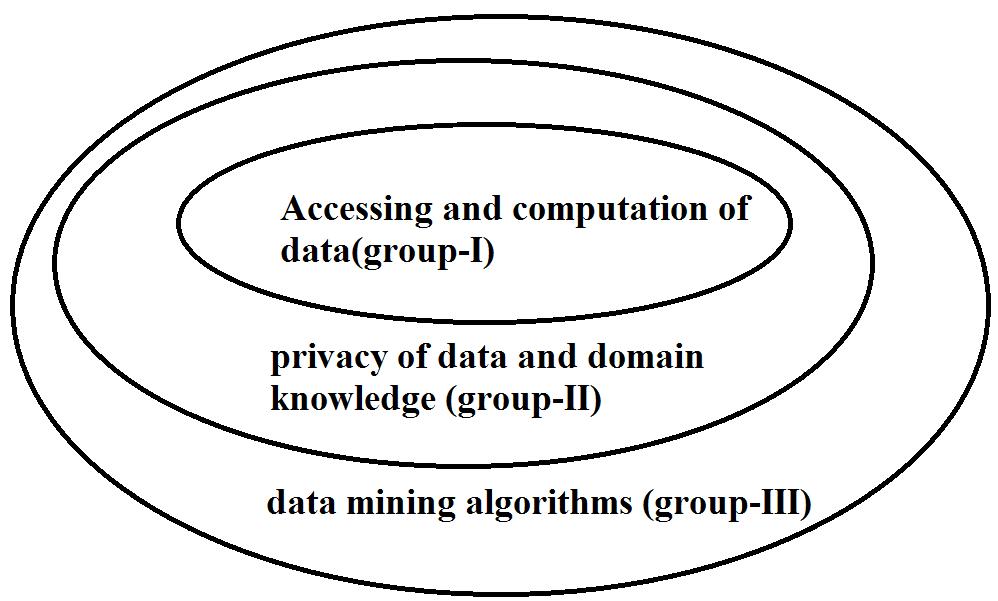
Fig1: processing of Big Data framework
- CONCLUSION:
For applications that concern for Big Data volumes, it is commonly the situation that data are physically dispersed at various locations. While research efforts established motivating patterns, existing methods can effort in offline fashion and are unable to help to manage Big Data situation in real time. For the most applications of Big Data, privacy issues mainly spotlight on excluding of third party from accessing original information. A system has to be considered so that unstructured data is linked all the way through their complex associations to form useful patterns, and expansion of data volumes. For managing big data concerning database system, necessary key is to expand to remarkably huge volume of data and suggest treatments for quality featured by our approach. In our work we put forward a novel approach that differentiates features of Big Data revolution. Our approach put forward important features of big data and that include: huge with heterogeneous and diverse data sources, large-volume of data represented by varied as well as diverse dimensionalities and Independent data sources.
REFERENCES
[1] E.Y. Chang, H. Bai, and K. Zhu, “Parallel Algorithms for Mining Large-Scale Rich-Media Data,” Proc. 17th ACM Int’l Conf. Multimedia, (MM ’09,) pp. 917-918, 2009.
[2] R. Chen, K. Sivakumar, and H. Kargupta, “Collective Mining of Bayesian Networks from Distributed Heterogeneous Data,” Knowledge and Information Systems, vol. 6, no. 2, pp. 164-187, 2004.
[3] P. Dewdney, P. Hall, R. Schilizzi, and J. Lazio, “The Square Kilometre Array,” Proc. IEEE, vol. 97, no. 8, pp. 1482-1496, Aug. 2009.
[4] P. Domingos and G. Hulten, “Mining High-Speed Data Streams,” Proc. Sixth ACM SIGKDD Int’l Conf. Knowledge Discovery and Data Mining (KDD ’00), pp. 71-80, 2000.
[5] G. Duncan, “Privacy by Design,” Science, vol. 317, pp. 1178-1179, 2007.